Last week, I wrote about how I gave AIs matrix IQ tests, and how they all failed multiple different tests.
But I also noticed, reading ChatGPT-4’s answers, that it sometimes used correct logic but still answered incorrectly because it misread the images.
That raised a question: What portion of its failure on the test was due to “bad thinking” vs just “bad vision”?
To answer that, I created a verbal translation of the Norway Mensa’s 35-question matrix-style IQ test — my goal was to describe each problem precisely enough that a smart blind person could, in theory, accurately draw the question (detailed examples below.)
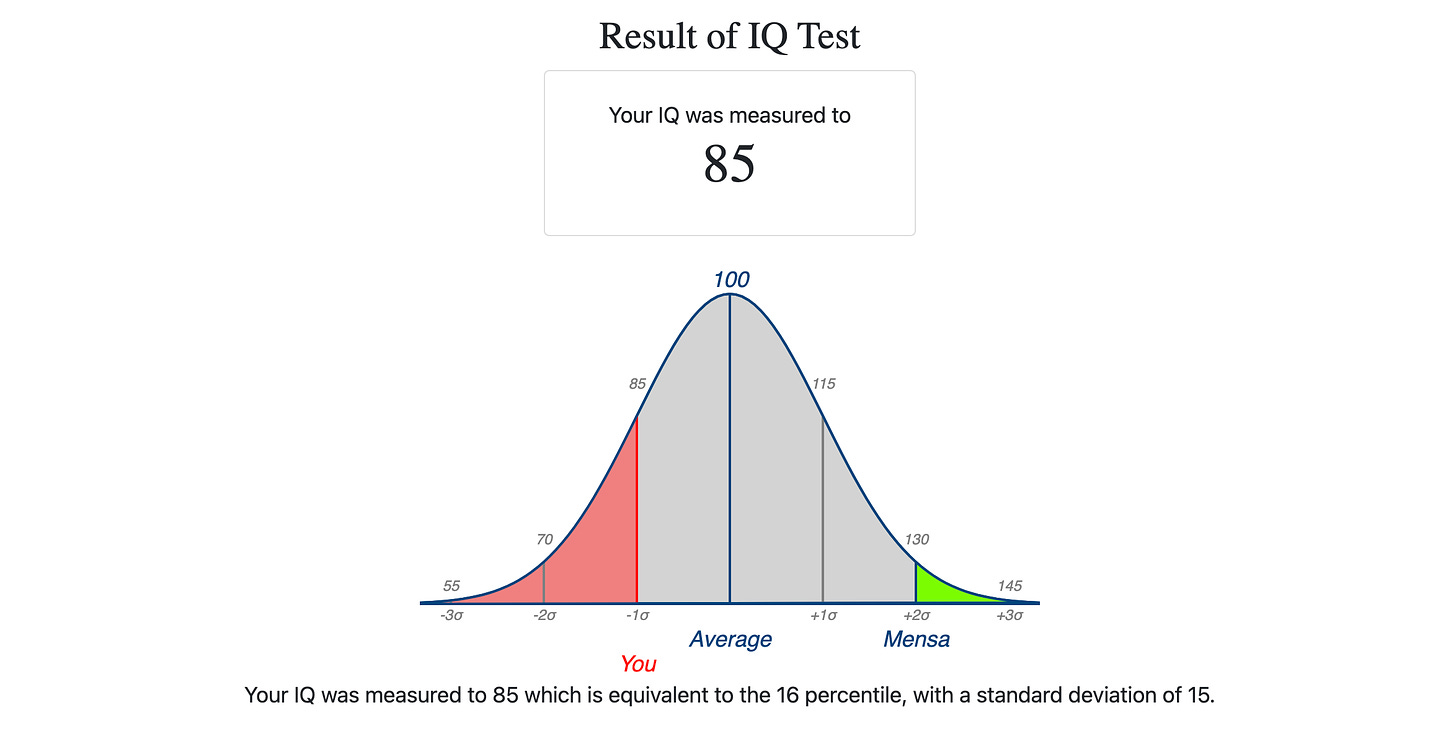
When the matrices were described to ChatGPT-4 in words, it finally got a scoreable IQ!
I administered the Norway Mensa test to it twice, and it averaged 13 correct answers out of 35 questions, which yields an IQ estimate of 85.
I also ran the quiz for other AIs, and here’s what I got:
Tests given in March 2024. The IQ test was Mensa Norway, with all questions verbalized as if one were giving the test to a blind person. The right-hand column shows the % of random-guesser simulations that the AI did better than, with ties ignored, over 70 questions (two test administrations.)
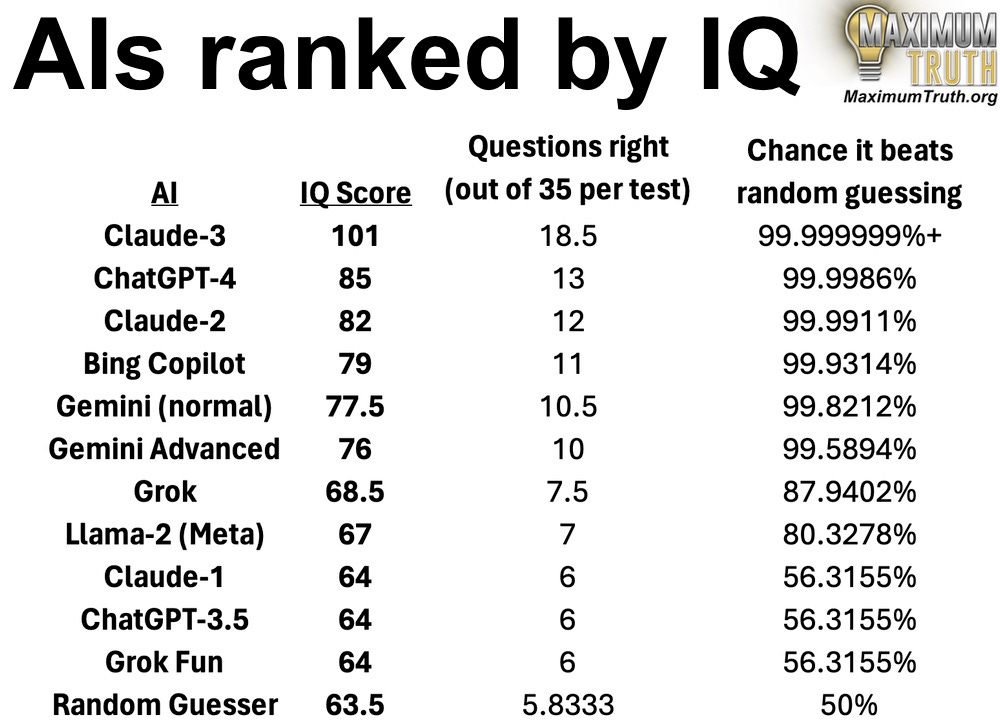
Every AI was given the test twice, to reduce variance. “Questions right” refers to the average number of correct questions, across two test administrations.
Although Norway Mensa refuses to score anything below 85, I noticed that each question is worth 3 IQ points at that range. So I used that to estimate the scores below 85. That’s not by-the-book enough for Mensa Norway, but I think it’s worth calculating. Just understand that random guessing gives a score of 63.5 — that should be understood as the baseline, which an AI can expect simply for realizing that it’s being asked to pick a letter, and spitting one out.
If you prefer a more concrete metric, instead look at the raw “questions right” column, or the last column, which gives the probability that the AI performed better than a random guesser would (which I calculated by simulating a million random-guessers taking the test; the numbers in the column show the percentage of simulations that the AI beat.)
I made this ranking because I find it fascinating.
It helps me know which AIs would be most productive for me to try.
It also helps me think about AI capability and AI existential risk.
I was already impressed by how ChatGPT-4 went from “unscoreable” to IQ 85, after I verbalized the questions. I was halfway through writing this post when Claude-3 came out, yesterday.
I’m amazed by its score.